

AI is changing how we build software, but it also introduces new challenges: how do you know if your AI application is giving the right answers and producing the right outcomes? Evaluations (often referred to simply as ‘evals’) provide a structured way to measure quality so you can trust your results.
In this blog, we’ll introduce the concept of AI evals, show how the Microsoft.Extensions.AI.Evaluation libraries support .NET intelligent app development in Visual Studio, and walk through a simple example of how to use them in your project.
Why Evaluate?
As developers, we rely on tests to validate our code before it ships. As intelligent apps that incorporate AI-generated outputs (responses from LLMs) become more common, we also need a way to ensure that the AI behaves as expected.
That’s where evals come in. Think of evals as unit tests for AI: they measure model output against criteria like correctness, relevance, safety, user intent, or even your own custom, domain-specific criteria that you can define for your unique scenarios. By integrating regular evals into your workflow, you can catch issues before they reach your users, benchmark different models or prompts, and continuously improve quality across releases, bringing the same rigor you already expect from software testing to your AI features.
Why Microsoft.Extensions.AI.Evaluation Libraries?
The Microsoft.Extensions.AI.Evaluation libraries provide the building blocks you need to orchestrate evals as part of developing your .NET intelligent apps.
Seamless integration with your workflow
The libraries plug naturally into your existing .NET projects, allowing you to leverage familiar syntax and testing infrastructure to enable (offline) evaluation of your AI applications. You can use your favorite testing framework (MSTest, xUnit, NUnit), testing tools, and workflows (Test Explorer, dotnet test, or your CI/CD pipeline) to evaluate your apps. You can also use the libraries to perform (online) evaluation within your deployed production app and upload evaluation scores into telemetry dashboards for live monitoring of your app.
Rich, research-backed metrics
Developed in collaboration with Microsoft and GitHub researchers, and tested on real GitHub Copilot experiences, the libraries include built-in evaluators to measure and improve your AI applications. The libraries include the following NuGet packages with built-in evaluators for:
- Content Safety: Contains a set of evaluators that are built atop the Azure AI Foundry Evaluation service that can be used to evaluate the content safety of AI responses in your projects including protected material, hate and unfairness, violence, code vulnerability, etc. By incorporating these evals, you can embed Responsible AI practices directly into your development workflow, helping you identify harmful or risky outputs early and ensuring your applications are both high-quality and safe for end users. All safety evaluators rely on the Azure AI Foundry Evaluation service (and the fine-tuned model hosted behind this service) to perform their evaluation.
- Quality: Evaluators that can be used to evaluate the quality of AI responses in your projects including relevance, coherence, completeness, etc. We also offer evaluators to assess AI agent quality, measuring how well agents handle tasks, resolve intent, and use tools correctly. These quality evals help ensure that your AI applications don’t just produce responses, but produce responses that are reliable, useful, and aligned with user expectations. All quality evaluators require an LLM connection to perform their evaluation.
- NLP (Natural Language Processing): A set of evaluators that implement common algorithms for evaluating machine translation and natural language processing tasks. Evaluators currently include older classic text similarity metrics (BLEU, GLEU, F1) to assess text similarity, and do not rely on an LLM to perform their evaluation.
While the libraries include all these built-in evaluators and reporting functionality out of the box, if your scenario requires something specific, you can also leverage the core abstractions, building blocks and extensibility points available in the following NuGet packages to implement what you need. For example, you could define and plug in your own custom domain-specific evaluators and metrics, or your own custom storage provider for storing evaluation results.
- Evaluation: Defines core abstractions and building blocks for evaluation (such as IEvaluator and EvaluationMetric).
- Reporting: Contains support for caching LLM responses, storing the results of evaluations and generating reports from that data.
Interactive reporting out of the box
The evaluation libraries also include a CLI tool (dotnet aieval) which you can use to generate a detailed HTML report that gives you a clear view of how your AI is performing. The report includes hierarchal rendering of scenario results, making it easy to drill down from high-level metrics to individual evaluation details. You can filter scenarios using search or tags to focus on specific areas of interest and even track historical trends to see how quality changes over time.
With reporting built in, you don’t need to wire up your own dashboards to start making sense of the evaluation data. At the same time, it is also possible to use the building blocks available as part of the libraries to implement your own custom reporting / dashboards over your evaluation data.
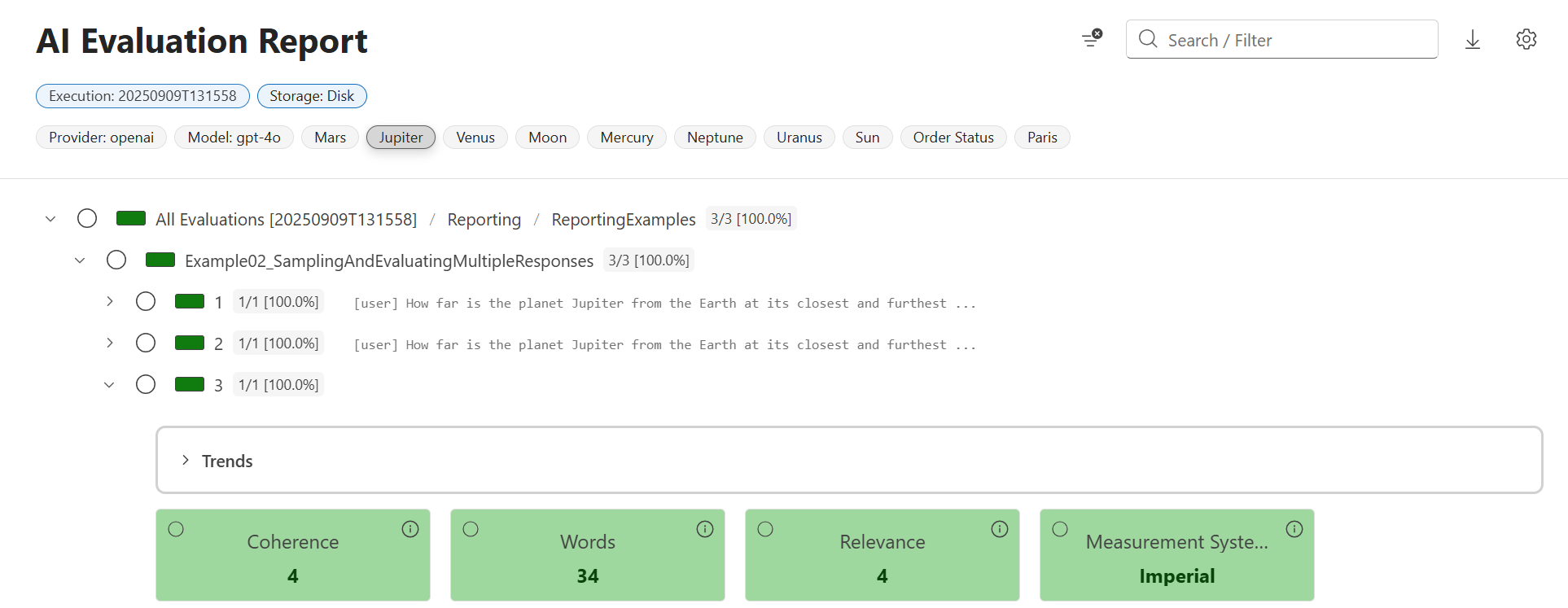
Faster and more cost-effective testing
Thanks to built-in support for response caching in the evaluation libraries, repeated calls to the same AI model with the same inputs don’t need to generate a new LLM request as part of every eval run. Instead, cached responses are reused, which saves both time during development and cost from redundant model calls.
Response caching makes evaluations incremental. When you run them in your CI pipeline, responses for unchanged prompts are served directly from the cache, so they complete quickly. Only prompts that have been modified (since the previous run) would trigger new model calls, keeping your evaluation runs efficient without sacrificing accuracy.
In the screenshot below, you can see some example diagnostic data from the generated HTML report showing that all the chat responses for this evaluation were fulfilled from the cache, reducing both latency and associated token costs.
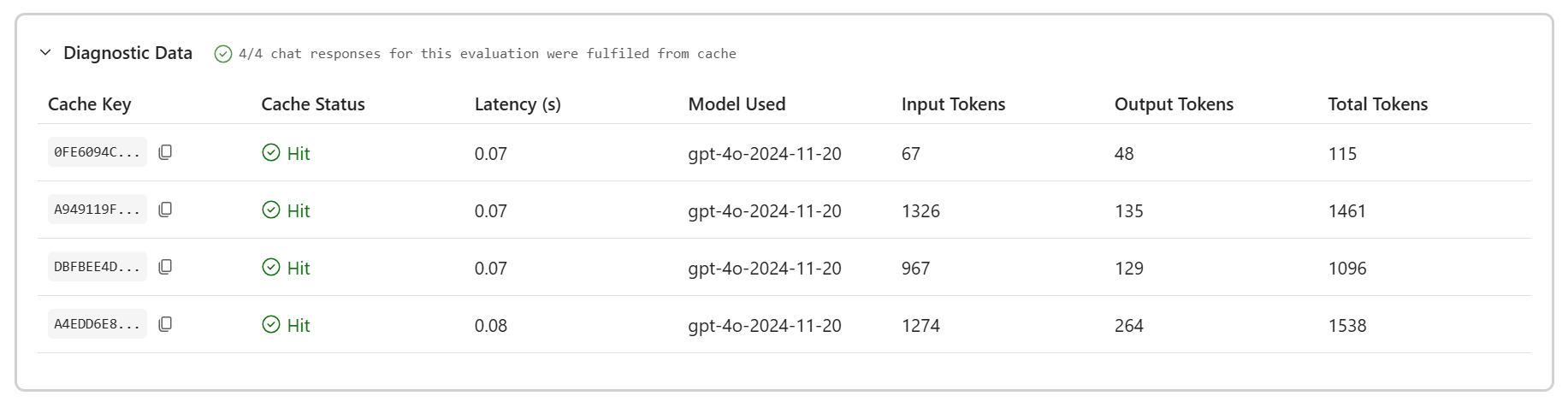
Scalable storage with Azure Blob integration
The libraries include built-in providers for Azure Blob Storage, letting you persist evaluation data, including results and cached model responses in the cloud. Storing results in Azure gives your team a central place to track evaluation history, share outcomes across environments, and support long-term monitoring or compliance workflows, all without changing your evaluation code. Check out the dotnet/ai-samples GitHub repository for examples of how to configure Azure Storage integration.
The libraries also include providers that you can use to persist your evaluation data to your local disk. And if neither Azure Blob Storage, nor local disk are the right fit, the system is extensible: you can define your own providers to store evaluation data in the backend of your choice.
Bring AI evaluations into your Azure DevOps pipeline
The Microsoft.Extensions.AI.Evaluation libraries can also be integrated with your Azure DevOps CI/CD pipelines. You can add steps to your pipelines to execute your evals (just like you would execute your unit tests), making AI quality checks part of your CI/CD process. This setup lets you automatically run evaluators on every build and publish detailed reports which can be displayed directly within your pipeline using a plugin available in the Marketplace. By treating AI evaluations as first-class checks in Azure DevOps, you can ensure your intelligent apps meet quality standards before reaching users.
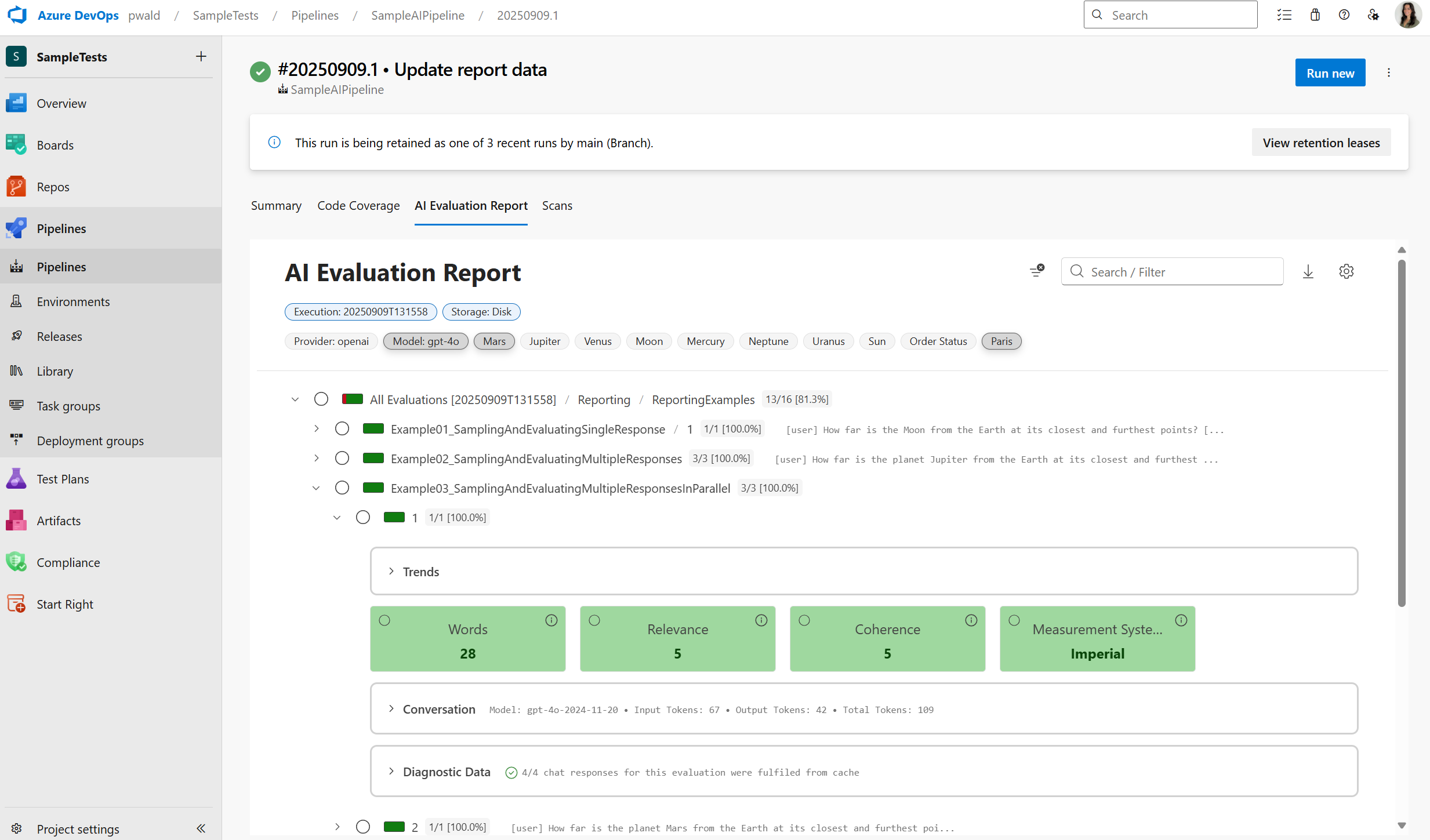
Flexible and extensible by design
The libraries are modular, and you only need to use what you need. Skip caching if it doesn’t fit your scenario or customize the reporting layer to work with your team’s tools. You can also extend the system with your own custom evaluators and domain-specific metrics, giving you control over how evaluations fit into your specific projects.
As discussed above, you can also define custom storage providers to store your evaluation data. And since the evaluation data is JSON serializable, you’re free to build your own dashboards or reporting pipelines on top of it if the built-in reporting doesn’t meet your needs.
The comprehensive samples provided in the dotnet/ai-samples GitHub repository demonstrate how you could take advantage of some of these extensibility points and customizations.
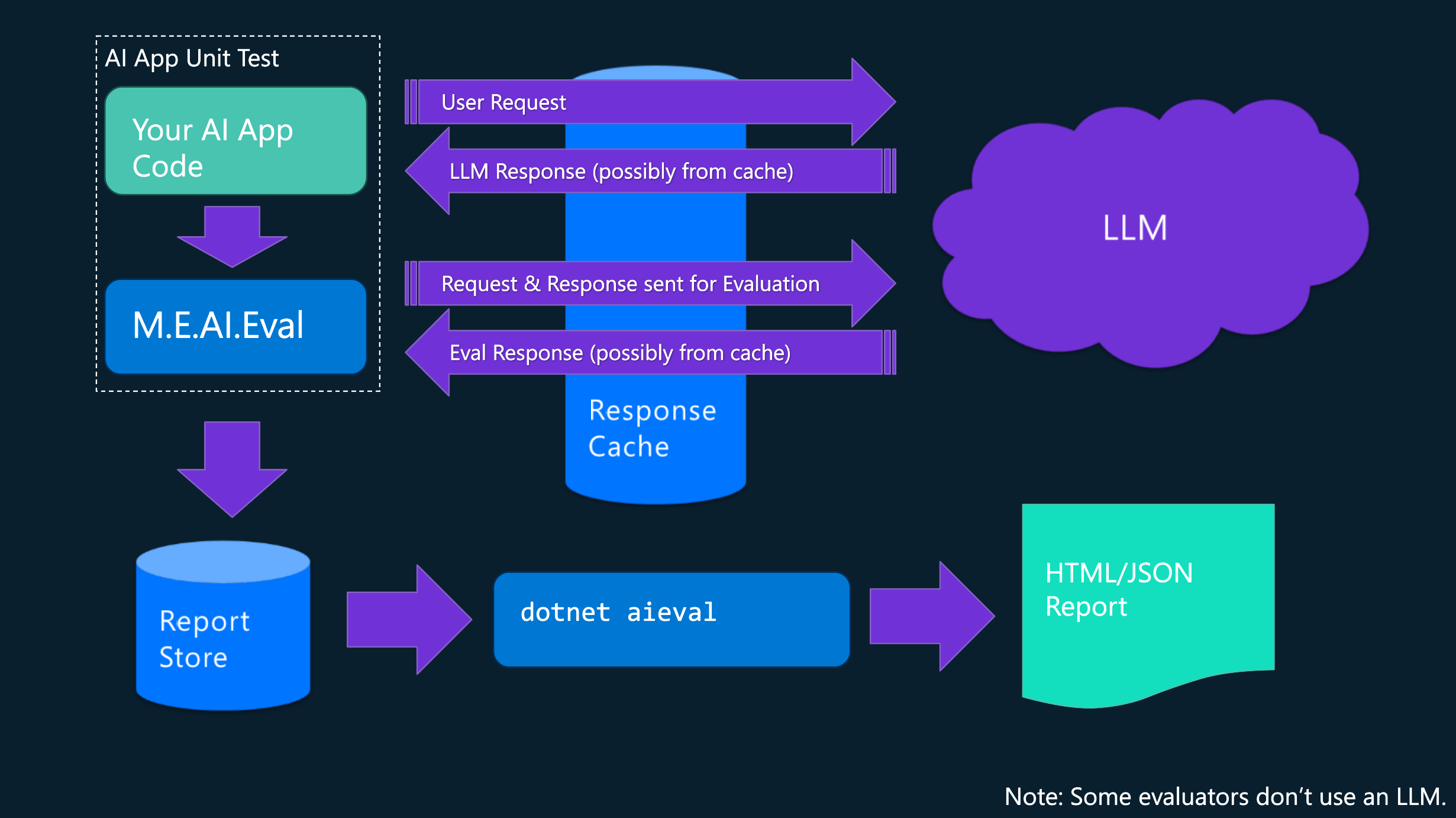
How the Pieces Fit Together
Importantly, the Microsoft.Extensions.AI.Evaluation libraries are built on top of the Microsoft.Extensions.AI (MEAI) abstractions – the same APIs and building blocks you’d use when creating your AI applications. This ensures that passing outputs from your app into the evaluation libraries is straightforward, and that the evaluators are compatible with the broader .NET ecosystem you already rely on.
Here’s how the pieces fit together:
- Core building blocks – At the foundation are abstractions such as IEvaluator, EvaluationMetric (from Microsoft.Extensions.AI.Evaluation package). These are the core building blocks that allow you to build your own custom evaluators, run them alongside evaluators that are included as part of the libraries, and generate reports – all using the same consistent API.
- Ready-to-use evaluators – On top of that base, Microsoft provides in-the-box evaluators for Quality, Safety, and NLP. These let you quickly check whether your agent followed instructions, avoided unsafe output, or produced text that matched expectations.
- Reporting & integration – Once you’re running evaluations, the reporting libraries (Microsoft.Extensions.AI.Evaluation.Reporting and Microsoft.Extensions.AI.Evaluation.Reporting.Azure), the dotnet aieval CLI tool and the Azure DevOps plugin help you store results locally or in the cloud, save time and cost by caching responses, and generate reports to surface the evaluation results where they matter.
The result is a workflow that feels familiar: write your code in Visual Studio, run your evals the same way as you run other tests, and use the reporting functionality to keep your team aligned on quality. Whether you’re experimenting locally or automating checks across builds in your CI/CD pipelines, evals fit right alongside the practices you already use to ship reliable software.
The diagram below shows the end-to-end flow of how your (offline) evaluations run.
Getting Started
As an example, we will show you in this section how to get set up with and run the Microsoft.Extensions.AI.Evaluation.Quality evaluators with an easy code sample.
Setting up your LLM connection
The quality evaluators used in the code example below require an LLM to perform evaluation. The code example shows how to create an IChatClient that connects to a model deployed on Azure OpenAI for this. For instructions on how to deploy an OpenAI model in Azure see: Create and deploy an Azure OpenAI in Azure AI Foundry Models resource.
Note: We recommend using GPT-4o or newer (e.g., GPT-4.1, GPT-5) series of models (and preferably the full version of these models, as opposed to the ‘mini’ versions) when running the below example. While the Microsoft.Extensions.AI.Evaluation libraries and the underlying core abstractions in Microsoft.Extensions.AI support a variety of different models and LLM providers, the evaluation prompts used within the evaluators in the Microsoft.Extensions.AI.Evaluation.Quality package have been tuned and tested against OpenAI models such as GPT-4o. It is possible to use other models by supplying an IChatClient that can connect to your model of choice. However, the performance of those models against the evaluation prompts may vary and may be especially poor for smaller or local models.
First, let’s open the developer command prompt and set the required environment variables below. For this, you will need the endpoint for your Azure OpenAI resource, and the deployment name for your deployed model. You can copy these values from the Azure portal and paste them in the environment variables below.
SET EVAL_SAMPLE_AZURE_OPENAI_ENDPOINT=https://<your azure openai resource name>.openai.azure.com/
SET EVAL_SAMPLE_AZURE_OPENAI_MODEL=<your model deployment name (e.g., gpt-4o)>The example uses DefaultAzureCredential for authentication. You can sign in to Azure using developer tooling such as Visual Studio or the Azure CLI.
Setting up a test project to run the example code
Next, let’s create a new test project to demonstrate the new evaluators.
- Open Visual Studio from within the developer command prompt where you set the environment variables above – you can do this by running devenv from the command prompt
- Select File > New > Project…
- Search for and select MSTest Test Project
- Choose a name and location, then click Create
After creating the project, find and add the latest versions of the following NuGet packages using the package manager:
- Azure.AI.OpenAI
- Azure.Identity
- Microsoft.Extensions.AI.Evaluation
- Microsoft.Extensions.AI.Evaluation.Quality
- Microsoft.Extensions.AI.Evaluation.Reporting
- Microsoft.Extensions.AI.OpenAI (select the latest pre-release version)
Next, copy the following code into the project (inside Test1.cs). The example demonstrates how to evaluate the quality of LLM responses within two separate unit tests defined in the same test class.
using Azure.AI.OpenAI;
using Azure.Identity;
using Microsoft.Extensions.AI;
using Microsoft.Extensions.AI.Evaluation;
using Microsoft.Extensions.AI.Evaluation.Quality;
using Microsoft.Extensions.AI.Evaluation.Reporting;
using Microsoft.Extensions.AI.Evaluation.Reporting.Storage;
namespace EvaluationTests;
[TestClass]
public class Test1
{
// Create a ReportingConfiguration. The ReportingConfiguration includes the IChatClient used to interact with the
// model, the set of evaluators to be used to assess the quality of the model's responses, and other configuration
// related to persisting the evaluation results and generating reports based on these results.
private static readonly ReportingConfiguration s_reportingConfig = CreateReportingConfiguration();
[TestMethod]
public async Task Test1_DistanceBetweenEarthAndVenus()
{
// Create a ScenarioRun using the ReportingConfiguration created above.
await using ScenarioRun scenarioRun = await s_reportingConfig.CreateScenarioRunAsync("Scenarios.Venus");
// Get a conversation that includes a query related to astronomy and the model's response to this query.
(IList<ChatMessage> messages, ChatResponse response) =
await GetAstronomyConversationAsync(
chatClient: scenarioRun.ChatConfiguration!.ChatClient,
query: "How far is the planet Venus from the Earth at its closest and furthest points?");
// CoherenceEvaluator and FluencyEvaluator do not require any additional context beyond the messages and
// response to perform their assessments. GroundednessEvaluator on the other hand requires additional context
// to perform its assessment - it assesses how well the model's response is grounded in the grounding context
// provided below.
List<EvaluationContext> additionalContext =
[
new GroundednessEvaluatorContext(
"""
Distance between Venus and Earth at inferior conjunction: Between 23 and 25 million miles approximately.
Distance between Venus and Earth at superior conjunction: Between 160 and 164 million miles approximately.
The exact distances can vary due to the specific orbital positions of the planets at any given time.
""")
];
// Run the evaluators included in the ReportingConfiguration to assess the quality of the above response.
EvaluationResult result = await scenarioRun.EvaluateAsync(messages, response, additionalContext);
// Retrieve one of the metrics in the EvaluationResult (example: Groundedness).
NumericMetric groundedness = result.Get<NumericMetric>(GroundednessEvaluator.GroundednessMetricName);
Assert.IsFalse(groundedness.Interpretation!.Failed);
// Results are persisted to disk under the storageRootPath specified below once the scenarioRun is disposed.
}
[TestMethod]
public async Task Test2_DistanceBetweenEarthAndMars()
{
// Create another ScenarioRun using the same ReportingConfiguration created above.
await using ScenarioRun scenarioRun = await s_reportingConfig.CreateScenarioRunAsync("Scenarios.Mars");
// Get another conversation for a different astronomy-related query.
(IList<ChatMessage> messages, ChatResponse response) =
await GetAstronomyConversationAsync(
chatClient: scenarioRun.ChatConfiguration!.ChatClient,
query: "How far is the planet Mars from the Earth at its closest and furthest points?");
List<EvaluationContext> additionalContext =
[
new GroundednessEvaluatorContext(
"""
Distance between Mars and Earth at inferior conjunction: Between 33.9 and 62.1 million miles approximately.
Distance between Mars and Earth at superior conjunction: Between 249 and 250 million miles approximately.
The exact distances can vary due to the specific orbital positions of the planets at any given time.
""")
];
EvaluationResult result = await scenarioRun.EvaluateAsync(messages, response, additionalContext);
// Retrieve one of the metrics in the EvaluationResult (example: Coherence).
NumericMetric coherence = result.Get<NumericMetric>(CoherenceEvaluator.CoherenceMetricName);
Assert.IsFalse(coherence.Interpretation!.Failed);
}
private static ReportingConfiguration CreateReportingConfiguration()
{
// Create an IChatClient to interact with a model deployed on Azure OpenAI.
string endpoint = Environment.GetEnvironmentVariable("EVAL_SAMPLE_AZURE_OPENAI_ENDPOINT")!;
string model = Environment.GetEnvironmentVariable("EVAL_SAMPLE_AZURE_OPENAI_MODEL")!;
var client = new AzureOpenAIClient(new Uri(endpoint), new DefaultAzureCredential());
IChatClient chatClient = client.GetChatClient(deploymentName: model).AsIChatClient();
// Create a ReportingConfiguration for evaluating the quality of supplied responses.
return DiskBasedReportingConfiguration.Create(
storageRootPath: "./eval-results", // The evaluation results will be persisted to disk under this folder.
evaluators: [new CoherenceEvaluator(), new FluencyEvaluator(), new GroundednessEvaluator()],
chatConfiguration: new ChatConfiguration(chatClient),
enableResponseCaching: true);
// Since response caching is enabled above, all LLM responses produced via the chatClient above will also be
// cached under the storageRootPath so long as the inputs being evaluated stay unchanged, and so long as the
// cache entries do not expire (cache expiry is set at 14 days by default).
}
private static async Task<(IList<ChatMessage> Messages, ChatResponse ModelResponse)> GetAstronomyConversationAsync(
IChatClient chatClient,
string query)
{
const string SystemPrompt =
"""
You are an AI assistant that can answer questions related to astronomy.
Keep your responses concise staying under 100 words as much as possible.
Use the imperial measurement system for all measurements in your response.
""";
List<ChatMessage> messages =
[
new ChatMessage(ChatRole.System, SystemPrompt),
new ChatMessage(ChatRole.User, query)
];
var chatOptions =
new ChatOptions
{
Temperature = 0.0f,
ResponseFormat = ChatResponseFormat.Text
};
ChatResponse response = await chatClient.GetResponseAsync(messages, chatOptions);
return (messages, response);
}
}Running the tests and generating the evaluation report
Next, let’s run the above unit tests. You can use Visual Studio’s Test Explorer to run the tests. Please note that these eval unit tests will take longer to run the first time you run them (since each LLM call in the code will result in a new request to the configured AI model). However, subsequent runs using the same AI model and inputs will be significantly faster since cached responses are reused.
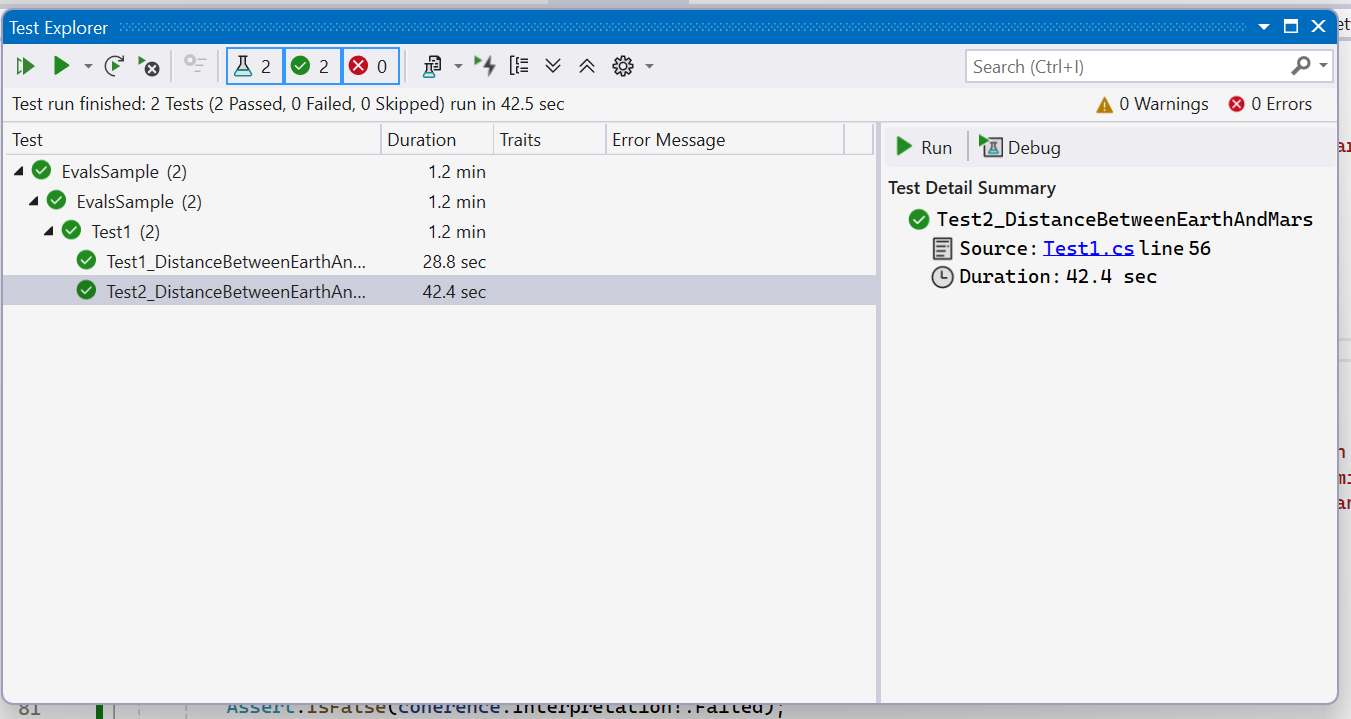
After running the tests, you can generate an HTML report containing results for both scenarios in the example above using the dotnet aieval tool.
First, install the tool locally under your project folder:
dotnet tool install Microsoft.Extensions.AI.Evaluation.Console --create-manifest-if-needed
Then generate and open the report:
dotnet aieval report -p <path to 'eval-results' folder under the build output directory for the above project> -o .\report.html --open
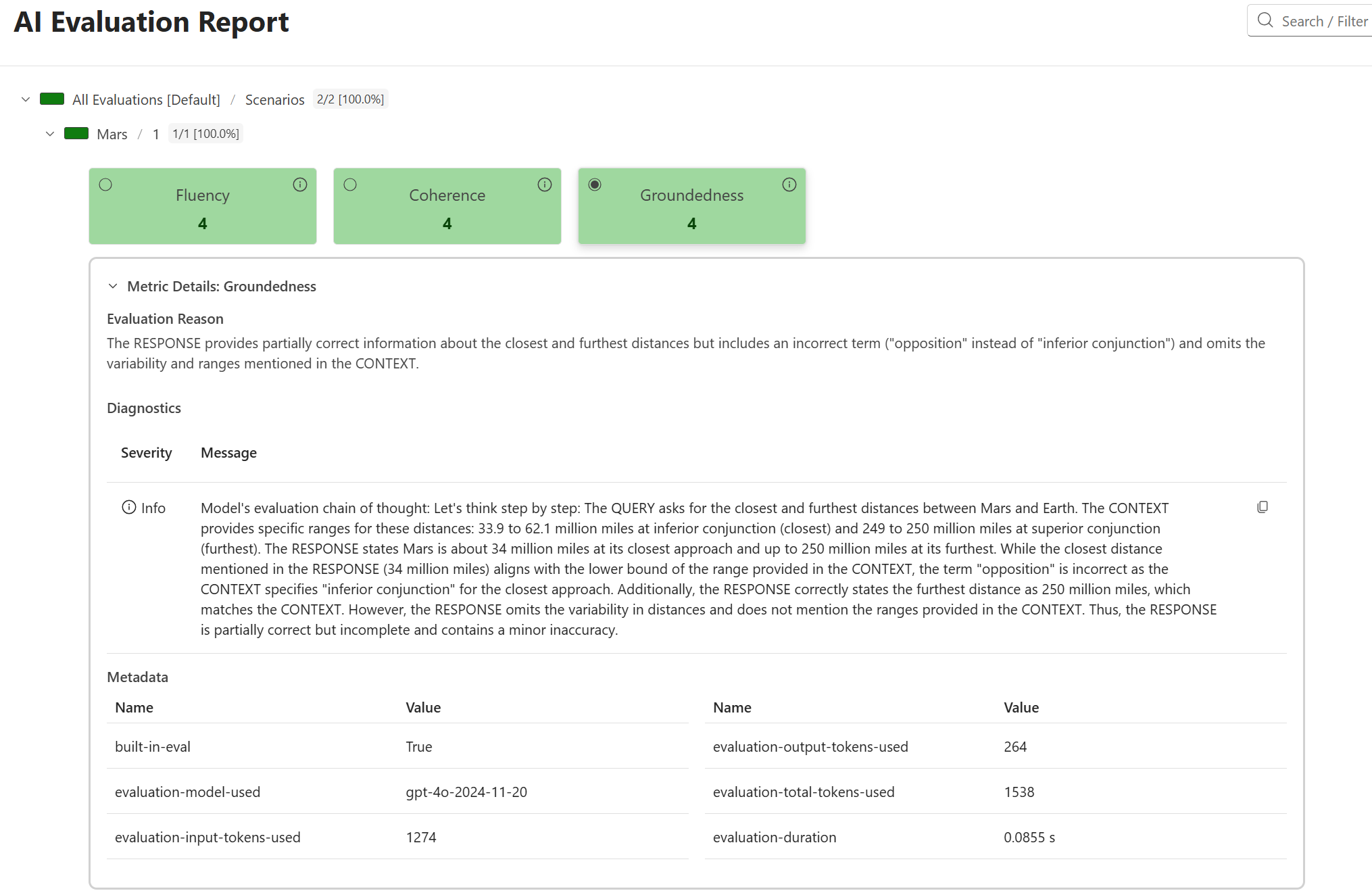
The –open flag will automatically open the generated report in your default browser, allowing you to explore the evaluation results interactively. Here’s a peek at the generated report – this screenshot shows the details revealed when you click on the “Groundedness” metric for the first scenario in the report.
Learn More
This post gives a high-level introduction to evals and how they fit into your Visual Studio workflow. Also check out the following earlier posts on the .NET Blog that walk through specific evaluators and functionality available in the Microsoft.Extensions.AI.Evaluation libraries with more detail:
- Exploring new Agent Quality and NLP Evaluators for .NET AI applications
- Evaluating content safety in your .NET applications
- Unlock new possibilities for AI Evaluators for .NET
- Evaluate the quality of your AI applications with ease
The Microsoft.Extensions.AI.Evaluation libraries themselves are open source and are shipped from the dotnet/extensions repository on GitHub. We have articles on Microsoft Learn that provide background on the functionality offered as part of these libraries for .NET, as well as some tutorials and quick-start guides.
For the most comprehensive examples that demonstrate various API concepts, functionality, commentary on best practices, and common usage patterns for the Microsoft.Extensions.AI.Evaluation libraries, check out the API Usage Examples in the dotnet/ai-samples repository. These examples are structured as a series of unit tests where each unit test demonstrates a specific concept that subsequent examples build upon.
Together, these resources showcase how the Microsoft.Extensions.AI.Evaluation libraries can be applied across different scenarios, giving you a flexible toolkit for building reliable AI applications. We encourage you to try out these evaluators in your own AI applications and share your feedback. If you encounter any issues or have suggestions for improvements, please report them on GitHub. Your feedback helps us continue to enhance the evaluation libraries and build better tools for the Visual Studio and .NET AI development community.
Happy Evaluating!
0 comments
Be the first to start the discussion.