
A team was running at 100% RU utilization. Throttles were compounding into retries. P99 latency was degrading. The assumption was obvious: provision more throughput.
They didn’t.
Instead, they found a single logical partition absorbing more than 80% of traffic. After fixing the data model—without scaling the database—RU utilization dropped to 20–35%, throttling vanished, and latency normalized.
That was the real-world case study Anurag Dutt shared in his Azure Cosmos DB Conf 2026 session, From Rising RU Costs to Stable Performance. One automated integration account was generating most writes. A partition key that looked reasonable (userId) became a system-wide bottleneck. As Anurag put it plainly: increasing RU doesn’t solve design problems—it only delays them.
That lesson echoed across Cosmos Conf. From OpenAI, Vercel, and Walmart, to engineers running Aure Cosmos DB inside Microsoft products, the pattern was consistent: Azure Cosmos DB doesn’t create bad design—it reveals it quickly. Whether the topic was data modeling, query shape, AI agent memory, change feed, or migration tooling, the same story appeared again and again: scale failures are almost always design failures.
Workloads are scaling faster than roadmaps
In the Cosmos Conf keynote, Jonathan Lee from OpenAI described running “thousands of tables” on Azure Cosmos DB for products that can go from zero usage to hundreds of millions of daily users almost overnight.
Guillermo Rauch, founder and CEO of Vercel, described Vercel’s deployments collection tripling in a few months due to agent-driven app creation.
The common thread: today’s workloads don’t scale on quarterly roadmaps. They scale on whatever just shipped.
Kirill Gavrylyuk, VP of Azure Cosmos DB, framed the challenge succinctly: AI changes what databases must do. They need to store unstructured, evolving data without rigid schemas; support semantic search alongside transactional queries; and expose higher-level “skills” that coding agents can directly invoke. Those demands sit on top of a year of Azure Cosmos DB improvements surfaced throughout the conference: hierarchical partition keys, partition-level auto-failover, fleet-wide throughput management, 99.999% availability across all consistency levels, and continued hardware evolution underneath the service.
These themes showed up everywhere. We dig into them below.
Throughput is partitioned – your access patterns have to match
Throughput in Azure Cosmos DB is evenly distributed across physical partitions. That sounds simple. The implications are not.
Andrew Liu’s whiteboard session laid out the mechanics – consistent hashing, RU pooling, and how Azure Cosmos DB scales horizontally – but also explained why bad partition keys are so destructive. If you provision 40,000 RU/s and get four partitions, each has 10,000 RU/s. If most traffic hits one partition, your effective throughput is 10,000 RU/s, no matter how much you provision.
That’s why partition keys like userId fail in practice when one “user” is actually a high-volume integration account. The fix isn’t pretty, it’s intentional. Add a time or workload dimension so load spreads across partitions. The throughput you were already paying for becomes usable.
partitionKey = userId + timeBucket // e.g. "user123_2026-04"Tural Suleymani’s Designing High-Scale Event-Driven Microservices with Azure Cosmos DB showed the same idea taken to its logical conclusion. His operational read model synthesizes partition keys around access patterns – tenant, status, and time – so dashboard queries are single-partition by construction. The key insight: partition keys don’t describe what data is, they describe how data is accessed.
Sid Anand from Walmart reinforced this from the production side, and Hasan Savran framed it from the modeling angle. The painful-to-change decisions – partition key, embed versus reference, indexing – are scaling decisions, not schema decisions.
Newer platform features make this work easier. Hierarchical partition keys remove the need to collapse composite keys into strings. Partition-level auto-failover avoids whole-account outages when a single partition fails. Combined with five nines of availability across all consistency levels, these features let teams design for access patterns without simultaneously underwriting availability risks.
For OpenAI, getting this wrong isn’t an option. Their requirement is scaling from zero to millions of QPS and from bytes to petabytes. Their solution – a multi-tenant abstraction layer in front of Azure Cosmos DB and aggressive multi-region replication – mirrors the same partition-and-replication mental model discussed throughout the conference.
Query cost isn’t abstract, it’s a multiplier
James Codella’s Querying and Indexing in Azure Cosmos DB: The Complete Guide made cost tangible. A cross-partition query fans out across every partition. A partition-filtered query hits one. A point read is a direct lookup.
| Query type | Typical RU cost |
| Cross-partition query | 100–400 RU |
| Partition-filtered query | 2–4 RU |
| Point read | ~1 RU |
The difference isn’t marginal. Typical cross-partition queries can cost hundreds of RUs. Partition-filtered queries land in the low single digits. Point reads cost about one RU. The fix is often a simple query rewrite: include the partition key or redesign the access path.
-- Fans out across every partition
SELECT * FROM orders WHERE status = 'pending'
-- Single-partition operation
SELECT * FROM orders WHERE tenantId = @tenantId AND status = 'pending'Indexing policy matters, too. Default indexing keeps reads cheap but inflates write cost. Patrick Oguaju of UK retailer Next shared a real workload that cut Azure Cosmos DB costs by more than 60% through better partitioning, indexing, and query shape. His takeaway was blunt: the issue wasn’t scale; it was design.
Guillermo Rauch of Vercel framed this as an “economical thinking model.” Developers see RU costs per query while writing code, turning cost into a design signal rather than a surprise at billing time. That immediacy is what makes the difference between a 100 RU query and a 1 RU point read a deliberate choice.
The keynote also went deeper than most database talks by connecting RU economics to hardware. Kirill brought Steve Berg, Corporate VP at AMD, on stage to discuss the EPYC processors underlying the Azure Cosmos DB fleet. The focus wasn’t peak frequency but performance per watt per dollar – critical as CPU usage shifts toward inference, orchestration, and agentic workloads. For Azure Cosmos DB users, the implication is simple: better query design extracts more value per RU, and the cost of each RU continues to improve underneath with no application change required.
Another maturity signal across sessions: stop trying to serve every query from one container. Tural’s reference architecture uses multiple containers, one optimized for writes, others projected via change feed for different read paths. Each query is partition-aligned; cross-partition queries disappear from hot paths.
AI agents made state a first-class problem
What felt genuinely new in 2026 was how clearly AI workloads reframed database design.
Guillermo Rauch described “agent ergonomics”: platforms originally built for humans now serve agents acting at massive scale. When agents can deploy software, the number of applications explodes. The patterns that survive are those with predictable per-operation cost and scale-to-zero behavior.
The core challenge is that LLMs are stateless. Chander Dhall’s Performance-Boosting Memory Patterns showed how memory strategy directly affects cost, recall quality, and user experience, sometimes by a 20× token-cost difference.
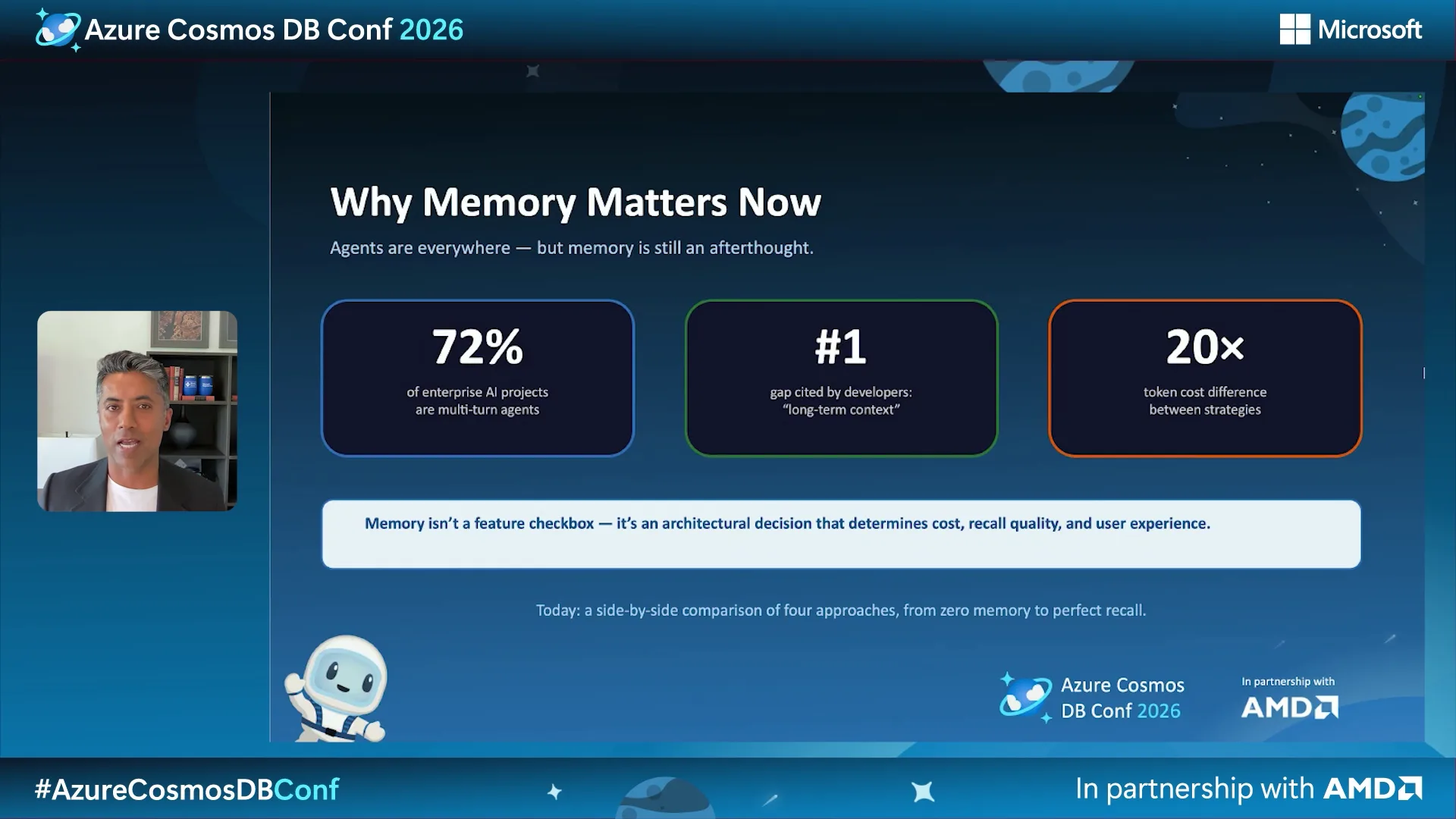
He walked through three patterns: sliding window memory, hierarchical memory tiers, and entity graphs. The common requirement is predictable, partition-aligned access to operational and vector data. Azure Cosmos DB fits naturally here because vector embeddings and operational context live together under the same partition key.
This is also the year semantic search fully converged into the core database engine. Full-text search, vector search, hybrid retrieval, and semantic re-ranking now run in the same query engine as transactional reads. Chat history containers partitioned by session can support recent-message reads, keyword search, and semantic retrieval without crossing partitions or systems.
Farah Abdou’s The Agent Memory Fabric made the value concrete. Her team replaced a multi-system AI stack (cache, relational DB, vector DB, coordination layer) with a single Azure Cosmos DB-backed fabric, cutting costs by 73% and latency by 65%. Lino Tadros and Yohan Lasorsa filled in the implementation details around chat history, semantic caching, and hybrid RAG.
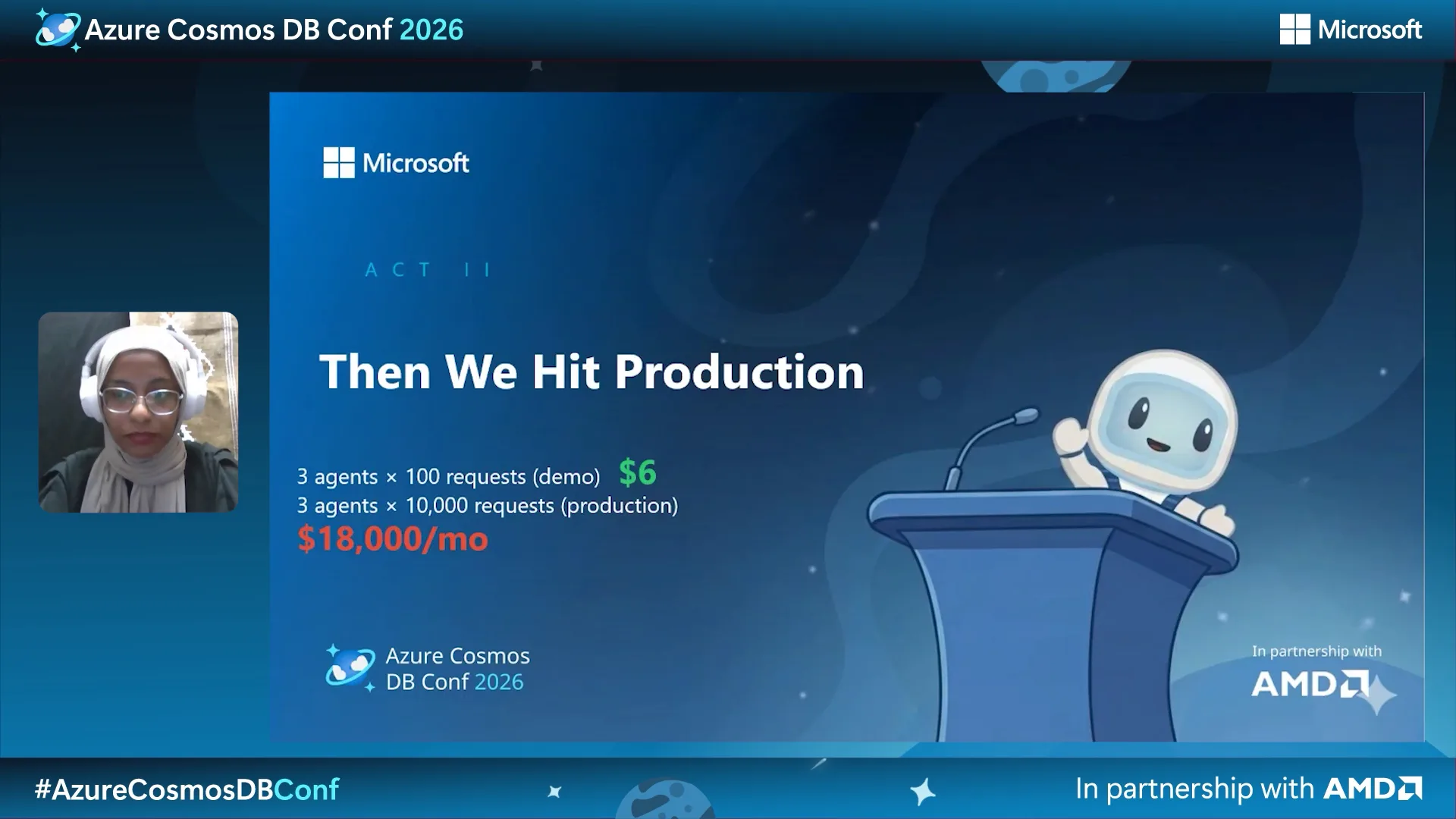
Mick Feller from Office Depot described a similar pattern in production: employee profiles and analytics stored together as agent memory, partitioned per user. Usage nearly doubled year over year, while the database scaling beneath it was uneventful. The takeaway was consistent: the database isn’t just persistence for AI – it’s the memory model.
Events over state
The most mature architectures across the conference had moved from storing mutable state to capturing immutable events and deriving state from them.
Divakar Kumar’s fraud detection system used event sourcing end to end. Transactions are events. ML inference reacts in real time. Queryable views are projections, not shared mutable state.
Eric Boyd illustrated the cost of ignoring coordination with a simple demo: two users buying the same seat simultaneously. Without deliberate concurrency control, last-write-wins silently overwrote reality. His session focused on the coordination primitives – optimistic concurrency, idempotency, distributed locks – that make event-driven systems correct instead of lucky.
Justine Cocchi’s deep dive on Change Feed showed how Azure Cosmos DB provides a built-in, ordered, partitioned event stream for every container. With continuation tokens per partition, processors scale horizontally and restart cleanly. Her demo highlighted “all versions and deletes” mode, making every change—including deletes—a first-class event.
response = container.query_items_change_feed(mode="AllVersionsAndDeletes")
continuation = container.client_connection.last_response_headers["etag"]
while True:
response = container.query_items_change_feed(
mode="AllVersionsAndDeletes",
continuation=continuation,
)
for doc in response:
op = doc["metadata"]["operationType"] # create | replace | delete
...
continuation = container.client_connection.last_response_headers["etag"]Tural Suleymani extended this into a full DDD microservices architecture, using Change Feed as the domain event spine. His key pattern: a transactional outbox written in the same partition as the aggregate, which eliminates dual-write hazards without two-phase commits.
From retail inventory to AI retrieval pipelines, the same shift appeared: stop querying shared mutable state; capture events and derive what you need.
Most teams are migrating, not starting fresh
Not everyone gets to design greenfield models. Two sessions addressed migration from opposite directions.
Sandeep Nair’s From MongoDB to Azure DocumentDB focused on API-compatible migration. Applications keep speaking MongoDB’s wire protocol while moving to Azure DocumentDB, an open-source, MongoDB-compatible engine governed by the Linux Foundation. His six-step playbook covered assessment, preparation, schema refinement, offline or online migration, validation, and cutover – with practical guidance on sharding, indexing, and change-stream–based CDC.
That path is right when the schema is solid and the engine is the bottleneck.
The opposite case—when the schema itself is the problem—was tackled by Sergiy Smyrnov in RDBMS to Cosmos DB with the Cosmos DB Agent Kit. An AI agent analyzed a classic relational app, proposed a denormalized document model, selected partition keys based on access patterns, rewrote the data access layer, and migrated data. The point wasn’t automation for its own sake; it was that the hardest design decisions are exactly the ones that benefit from structured, reviewable workflows.
Different paths, same lesson: you cannot skip access-pattern design.
The discipline behind the patterns
The strongest throughline of Azure Cosmos DB Conf 2026 wasn’t any single feature or pattern. It was a discipline shared by teams working in completely different domains: treat RU metrics as engineering signals, design partition keys around real access patterns, model events as first-class, and consider the database part of the application architecture, not an afterthought.
Jonathan Lee from OpenAI summarized it simply: ship, learn, iterate. Guillermo Rauch added the business framing: modern engineers participate directly in scaling decisions.
If you want the mental model behind all of this—replica sets, hashing, RU pooling—Andrew Liu’s whiteboard session Behind the Scenes: How Azure Cosmos DB Runs Under the Hood is the closest thing to ground truth.
What made the conference compelling wasn’t individual fixes. It was watching teams arrive independently at the same discipline. And that discipline has to come before production, not after.
Keep Going
All Azure Cosmos DB Conf 2026 sessions are free and on demand:
- 🎥 Watch the full playlist: aka.ms/CosmosConf26Playlist
- 📇 Browse by speaker and session: developer.azurecosmosdb.com/conf
- 🏆 Complete the Azure Cosmos DB Skills Challenge (through May 8) and apply for a free DP‑420 certification voucher
- 🛠️ Try it locally with the Azure Cosmos DB emulator in Docker
0 comments
Be the first to start the discussion.