

This is the fifth article in a series about Agent Experience (AX): the practice of making AI coding agents work correctly with your technology. The series covers what you can and can’t control in the agent stack, how to measure whether your extensions are helping or hurting, and how to iterate toward better outcomes.
Everything we’ve covered so far assumed the model has some training data about your technology. Maybe it’s outdated, maybe it’s biased toward a competitor, but there’s something in the weights to work with. For proprietary code, internal SDKs, and custom frameworks, there’s nothing.
In the previous article, we covered how extensions compete for the context window and interfere with each other. That assumed your extensions were correcting or supplementing what the model already knows. This article is about a different problem: what happens when you’re teaching from scratch.
The zero-knowledge starting point
When the model has seen your technology during training, you’re working with defaults. Bad defaults, sometimes, but defaults nonetheless. The model has opinions about your API shape, your naming conventions, and your error handling patterns. Your agent extensions correct those opinions, fill gaps, and steer the model toward current best practices.
When the model has never seen your technology, however, there are no defaults to correct and nothing to build on. It has a void, and voids don’t stay empty.
The closest-match trap
Models typically don’t say “I don’t know.” When a developer asks an agent to use an unfamiliar API, the model doesn’t flag uncertainty, pause, or ask for documentation. It finds the closest match in its training data and generates code as if that match were your technology.
Say your internal SDK has a method called SessionManager.initialize() that takes a configuration object with specific required fields. The model has never seen it. But it’s seen similar patterns in AWS SDK, Azure SDK, Firebase, and a dozen other libraries. It picks whichever one feels closest based on context clues (naming conventions, workspace structure, existing imports) and generates code that follows that SDK’s patterns. And to the model it doesn’t matter that the arguments are in the wrong order, the initialization flow assumes a builder pattern your library doesn’t use, and the error handling follows conventions from a completely different ecosystem.
The code looks plausible. That’s the trap. It uses your function names (because you mentioned them in the prompt or they appear in workspace files), it follows reasonable patterns, it might even compile if your language is forgiving enough. But it’s wrong in ways that only someone who knows your SDK would catch. Would a developer spot this in code review? Probably. Would they spot it across 20 files the agent generated in a single session? That’s harder.
How would you know which SDK the model decided yours looks like? You wouldn’t. Not unless you run a baseline evaluation.
What the baseline tells you
In the third article, we introduced baseline measurement: running a scenario without extensions to see what the model does on its own. For public technologies, the baseline shows you where the model gets things right and where it stumbles. For proprietary code, it tells you something more fundamental: what the model thinks your technology is.
Run a scenario that asks the agent to build something with your internal SDK. Don’t provide extensions, instruction files, or extra context. Just the workspace with your code and the developer’s prompt. Look at what the model generates.
Does it default to specific cloud patterns? Does it use REST conventions when your API is gRPC? Does it treat your authentication library like it’s OAuth when it’s something custom? The baseline reveals the model’s closest match, and that match is what your extensions need to override.
This matters because the closest match shapes every assumption downstream. It’s not just one wrong API call. It’s the initialization pattern, the error handling style, the async model, the naming conventions: all inherited from whatever public technology the model mapped yours to. Your extensions don’t just need to provide the right answer. They need to displace an entire mental model the model built from the wrong source.
Without a baseline, you’re guessing what to teach. With one, you know exactly what the model defaults to and can target your extensions accordingly.
Teaching from scratch vs. correcting misconceptions
There’s a fundamental difference between building extensions for technology the model knows and technology it doesn’t.
When the model has training data, your job is correction. The model knows something about your API, and your extension nudges it toward the current, correct version. An instruction file that says “use v3 of the SDK, not v2” works because the model understands the concept of your SDK. It just has the wrong version. The correction is small, the context cost is low, and the model fills in the gaps from its training.
When the model has no training data, your job is education. You’re not correcting a misconception, you’re building understanding from nothing. An instruction file that says “use v3 of the SDK” doesn’t help when the model doesn’t know the SDK exists, what it does, or how its API surface works. The model needs context it can’t infer.
This changes the design of your extensions in concrete ways:
| Correcting (known tech) | Teaching (unknown tech) | |
|---|---|---|
| What to provide | Deltas from what the model knows | Full mental model + API surface |
| Instruction style | “Use X instead of Y” | “X is a library that does Z. Here’s how it works.” |
| Context cost | Low (small corrections) | High (bootstrapping knowledge) |
| Error tolerance | Model self-corrects from training | Model repeats wrong patterns without correction |
| Extension types | Instruction files often sufficient | Multiple extension types needed together |
Correcting the model costs a few hundred tokens. Teaching it from scratch can cost thousands.
What to teach first
When you’re teaching from scratch, order matters. The model needs concepts before it can use details. Dump your full API reference into a skill, and the model has the what without the why or the how. It’ll treat your API like a lookup table, matching function signatures to the developer’s request without understanding when to use which one.
Think of it as a bootstrapping hierarchy:
- What this technology is and what problem it solves. One or two sentences. “Contoso Identity is an authentication library for internal services. It handles service-to-service auth using mutual TLS, not OAuth.” This alone tells the model to stop mapping your library to OAuth patterns.
- Core concepts and mental model. The 3-5 concepts a developer needs before writing their first line of code. Session lifecycle, credential types, scoping rules, whatever is unique to your technology. This is where you override the model’s closest-match assumptions.
- API shape and conventions. How the API is structured: naming patterns, initialization flow, method signatures for the most common operations. Not the full reference, just enough to write typical code correctly.
- Common patterns and workflows. The 3-5 things developers actually do with your technology. “Here’s how you authenticate a request.” “Here’s how you handle token refresh.” Code samples with annotations.
- Edge cases and gotchas. The things that trip up even developers who know the SDK. Important, but only useful after the model understands the basics.
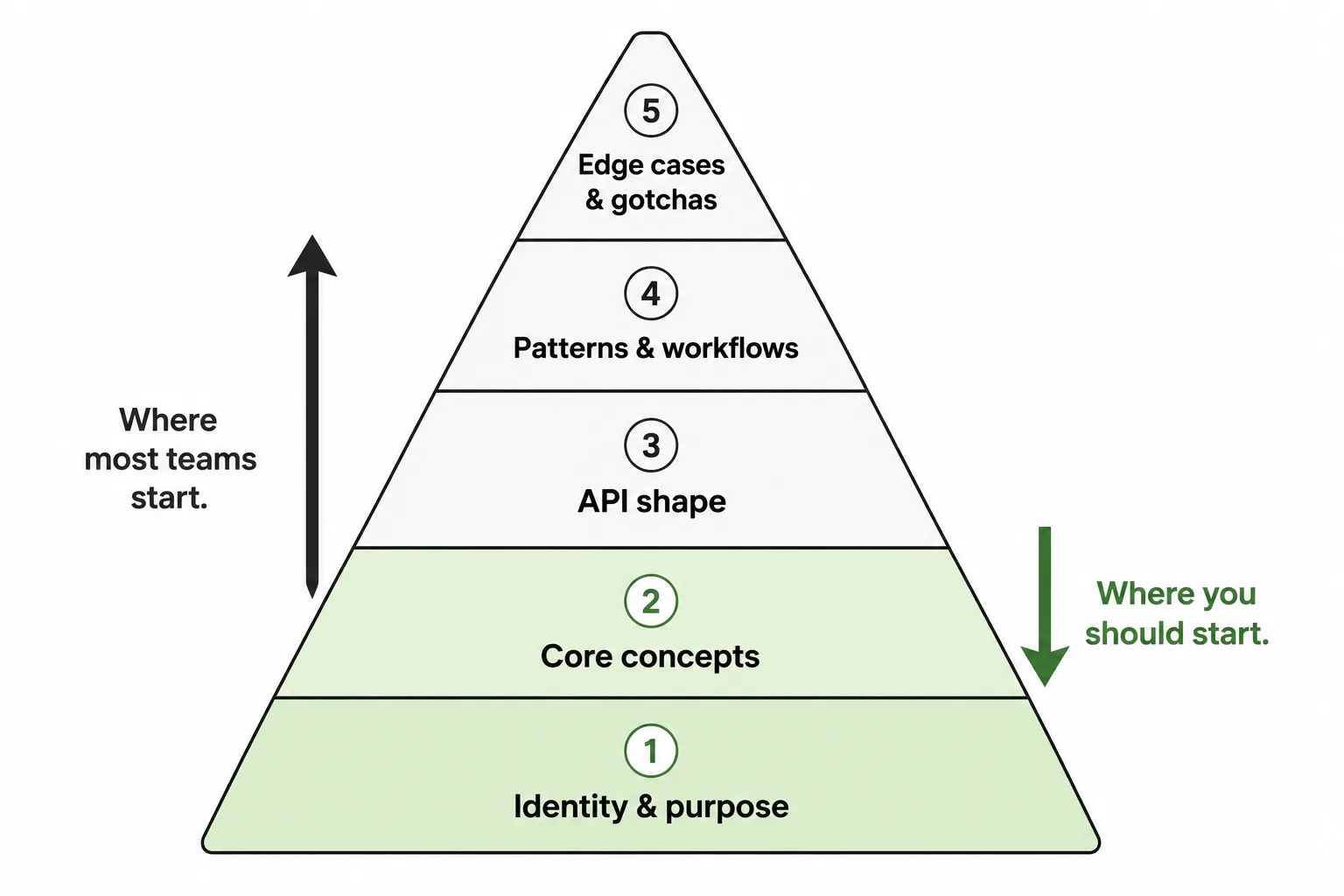
Most teams start at level 5 because that’s where they feel the pain. They build an extension that says “don’t forget to call dispose() on the session” without teaching the model what a session is or how to create one. The model dutifully adds session.dispose() to code that never initialized a session in the first place.
Start at the bottom, because that’s what stops the model from defaulting to the wrong mental model.
Practical extension patterns for zero-knowledge scenarios
No single extension type covers everything the model needs to learn. For proprietary technology, you typically need a combination, each covering a different layer of the bootstrapping hierarchy.
Instruction files for identity and conventions
Instruction files (AGENTS.md) are the lightest-weight way to establish what your technology is. They’re included in every prompt, which makes them powerful but also expensive if you’re not careful. Keep them short: the identity of your technology, core conventions, and what it’s not. Everything else belongs in tools the model can call on demand.
For unknown technology, the instruction file’s job is to prevent the closest-match trap. It doesn’t need to teach the entire API. It needs to tell the model: this is what we use, this is how it works at a high level, and here’s what it’s not.
## Contoso Identity
This project uses Contoso Identity for all service authentication.
Contoso Identity uses mutual TLS with short-lived certificates, NOT OAuth.
Key conventions:
- Initialize sessions with `SessionManager.create(config)`, not constructors
- Sessions are scoped to a single service pair
- Always call `session.close()` when done (sessions hold TLS connections)
- Error responses use `IdentityError` with numeric status codes, not HTTP status codes
Notice, that the instruction file explicitly states what the technology is not. That’s the override. Without “NOT OAuth,” the model defaults to OAuth patterns because that’s the closest match it has for “authentication library.”
MCP servers for current API surface
Instruction files provide framing. But when the model needs the exact method signature, the current parameter schema, or the list of available operations, it needs a way to ask for specifics.
The obvious first move is to point the agent at your documentation website and let it figure things out. That works for small APIs with concise docs, but you don’t control what the agent gets back. Web pages include navigation, sidebars, related links, and other content that wastes tokens without helping. The agent might land on the wrong page, read an overview when it needed a reference, or fetch outdated cached content. You could put your API reference in a skill, but skills deliver static content: the model gets the whole document whether it needs all of it or not. A local search index over your docs gives the model targeted results, but every developer on the team needs to build and maintain that index themselves, and when the API changes, every copy is stale until someone remembers to rebuild. You could put it in instruction files, but those are included in every prompt, and a full API reference would consume thousands of tokens on every turn whether the model uses your API or not. What you want is something the model can call on demand, with parameters, that’s centrally maintained so it gets exactly what it needs and nothing more.
That’s what MCP servers are for. The model asks “what does SessionManager.create() accept?” and your server returns the signature, the required fields, and a usage example. Tokens spent only when needed, scoped to what the model actually asked for.
For proprietary tech, the MCP server is often the only source of ground truth. The model can’t fall back to training data, so the server needs to return complete, specific responses. Not “see the docs for details,” but the actual interface, parameters, and return types.
Keep responses focused though. Return what the model needs for the current task, not your entire API surface. A tool that returns 50 method signatures when the model asked about authentication initialization is wasting tokens and pushing useful context out of the window. Return the minimum viable context, and make it precise.
Skills for guided workflows
Skills work well for the middle layers of the bootstrapping hierarchy: common patterns and workflows. A skill that walks the model through “how to set up service authentication with Contoso Identity” provides the step-by-step pattern the model can’t infer from training.
The key for unknown technology: don’t assume prior knowledge. A skill for a well-known framework can say “add the middleware to your Express app.” A skill for your internal framework needs to explain what the middleware is, where it goes, and why. The model has no background to fill in the gaps.
Reference implementations in the workspace
Sometimes the most effective teaching tool isn’t an extension at all. It’s existing code in the workspace.
The model reads workspace files during context assembly (as we covered in the second article). If your repository has well-structured examples of how to use your internal SDK correctly, the model pattern-matches against them. For proprietary code, this is powerful: the model can’t draw on training data, so workspace code becomes its primary reference.
The catch: the workspace code has to be good. If the existing code uses deprecated patterns or inconsistent conventions, the model learns those instead. The workspace is a teaching surface whether you intend it to be or not.
The compound effect
Here’s the part that makes this problem more tractable than it sounds. Most proprietary technology doesn’t exist in a vacuum. It builds on public foundations the model already knows.
Your internal SDK wraps REST APIs. Your authentication library issues JWTs. Your deployment tool generates Kubernetes manifests. Your data layer uses SQL. The model knows REST, JWTs, Kubernetes, and SQL. You don’t need to teach any of that. You need to teach what’s different about your implementation.
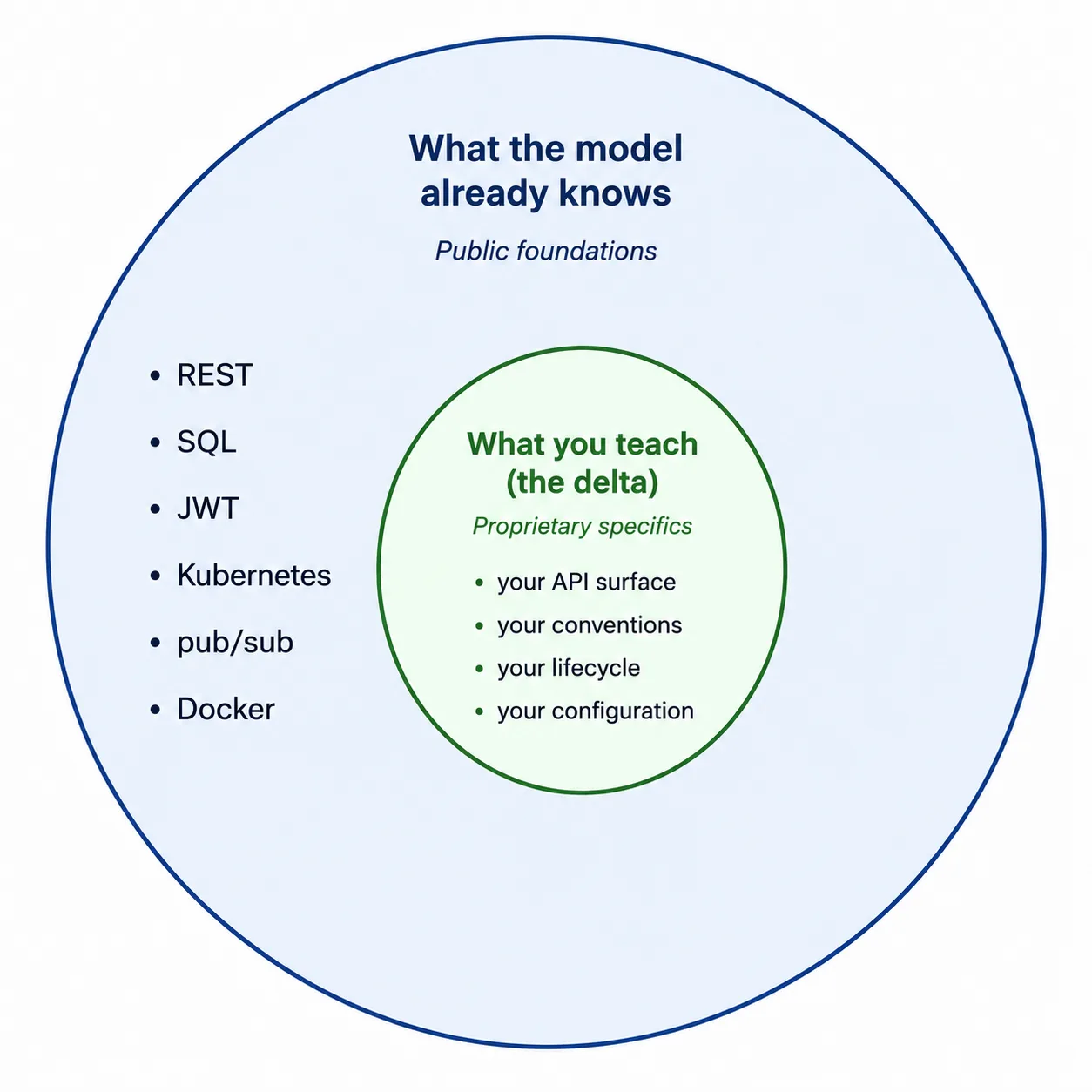
How much of your technology is actually novel? In most cases, it’s less than you’d think. The protocol is standard. So is the data format and the deployment target. What’s proprietary is the specific API surface, the conventions, lifecycle, and configuration. That’s a much smaller teaching surface than “everything.”
Map your technology to public foundations explicitly:
| Your technology | Model already knows | You teach the delta |
|---|---|---|
| Internal auth library | JWT, TLS, certificate patterns | Your initialization flow, session lifecycle |
| Custom ORM | SQL, common ORM patterns | Your query builder syntax, migration conventions |
| Internal deployment CLI | Kubernetes, Docker, CI/CD concepts | Your specific commands, configuration format |
| Proprietary event bus | Message queues, pub/sub patterns | Your topic naming, serialization requirements |
The model doesn’t need to learn event-driven architecture from scratch. It needs to learn that your event bus uses EventBroker.subscribe(topicPattern, handler) instead of the Kafka consumer pattern it would otherwise default to. That’s a targeted correction, not a full education.
Use what the model already knows. Teach only the delta. That’s how you keep context costs manageable for proprietary tech.
Error messages as a teaching surface
In the second article, we covered how agents use error messages to self-correct during iteration. For public technology, error messages supplement what the model already knows. For proprietary technology, they might be the only feedback the model gets when something goes wrong.
When the model generates wrong code for your internal SDK, it uses the closest-match pattern, the code fails, and the agent reads the error message. If your error says:
Error: Invalid configuration
The agent has nothing to work with. It’ll try variations of the same wrong pattern, burning through turns and tokens without making progress. Eventually it gives up or asks the developer.
Now compare:
Error: Invalid configuration for SessionManager.create().
Required fields: serviceId (string), targetService (string), certPath (string).
Received: { clientId, scope } which appears to be an OAuth configuration.
See: internal-docs/auth/session-setup.md
The agent knows exactly what’s wrong and what the correct pattern looks like. It can self-correct in one turn instead of ten. Notice, that the { clientId, scope } callout is particularly valuable: it tells the agent (and the developer) that the model defaulted to OAuth patterns, confirming the closest-match behavior and pointing directly at the fix.
When the model has no training data to fall back on, how does it learn from mistakes? Through your error messages. Every clear, specific error is a teaching opportunity that fires exactly when the model gets something wrong. For proprietary technology, error messages aren’t just diagnostics. They’re part of your extension strategy.
The cost of teaching
Everything we’ve discussed costs tokens. Instruction files, MCP server responses, skill definitions, reference code in workspace files, verbose error messages: all of it competes for the same finite context window.
The third article introduced the cost dimension: measuring not just whether outcomes improve, but what they cost in tokens and turns. For proprietary technology, this dimension matters more, because bootstrapping is expensive.
An agent working with a well-known framework might need 500 tokens of extension context to correct a few defaults. An agent working with your proprietary SDK might need 3,000 tokens just to understand what the technology is before it can write a single line of code. That’s 2,500 tokens not available for workspace context, conversation history, or other extensions.
The cost is real, and it’s higher than correction. For proprietary technology, you’re paying more per scenario for the agent to be useful. The question isn’t whether it costs more. It’s whether the outcomes justify the cost.
Summary
When the model has never seen your technology, the AX challenge changes fundamentally. There are no defaults to correct, and the model fills the void by mapping your code to the closest public technology it knows. Your baseline reveals that mapping, and your extensions need to override it.
Teach in layers: identity and conventions first, then concepts, then API surface, then patterns. Use what the model already knows about public foundations and teach only the delta. Make error messages a teaching surface that fires exactly when the model gets things wrong. And track the cost, because bootstrapping is more expensive than correcting.
In the next article, we’ll step back from individual extensions and look at evaluation at a broader scale: what AI benchmarks are actually measuring, and why their scores might not tell you what you think they do.
Excellent piece — the closest-match trap and the bootstrapping hierarchy are the clearest treatment of zero-knowledge AX I've seen, and "the workspace is a teaching surface whether you intend it or not" is exactly right.
One thing I've been measuring that sits right at the edge of this: everything here assumes the agent, once taught, wants to use what it's been taught — which holds for the honest-ignorance case you're describing. But I've been running adversarial trials where the agent is under task-completion pressure, and there the dynamic flips: a perfectly-taught agent will still route around a known convention when...
What you’re describing is something we’ve observed too, but I’d caveat it a bit. The “dispose()” example is the model not understanding the convention deeply enough rather than routing around a known convention under pressure. That’s still a teaching problem. That said, instruction-following is probabilistic: you can’t get guarantees, and the results will vary based on what’s in the context.