



The Model Context Protocol (MCP) is quickly becoming a common way for AI agents to discover and use tools. It provides a consistent interface to databases, APIs, file systems, and third-party services, which makes it easier to plug capabilities into agent workflows.
However, MCP standardizes the execution surface without defining how that surface should be governed. Tool definitions are fed directly to the model, tool servers can be hosted by anyone, and there is no built-in point where policy is evaluated before a call is executed.
To address that gap, we’ve been building a runtime governance layer for MCP tool execution. This post summarizes the rationale and introduces the Agent Governance Toolkit (AGT), an open-source project aimed at adding policy enforcement around tool calls.
How MCP tool execution works – and where trust breaks down
When an MCP client connects to a tool server, it receives a list of tool definitions (names, descriptions, and parameter schemas). The model uses those descriptions to choose a tool and construct arguments. The client serializes the request, sends it to the server, and the server executes it.
What’s missing is a built-in checkpoint that can answer a simple question before execution: is this agent allowed to invoke this tool, with these arguments, at this time?
That implicit trust can be fine in a small demo, but it becomes risky once MCP tool servers are connected to systems with real access controls, compliance requirements, and sensitive data. In practice, the gap is between “the model decided to call the tool” and “the call was validated as permitted, properly scoped, and auditable.”
The MCP attack surface is real and growing
This isn’t just theoretical. The OWASP MCP Top 10 outlines common risk categories for the ecosystem, and the surface area is expanding as implementations mature. For example, the NVD entries for CVE-2025-49596 and CVE-2025-66416 describe high-severity issues in MCP-related tooling/SDKs (including a reported unauthenticated RCE in MCP Inspector and a DNS rebinding issue in the Python SDK, respectively). These are implementation bugs that require SDK patches, but they also reinforce a broader point: security work is needed at every layer, including governance.
The OWASP Agentic Top 10 describes broader agentic risk categories, and MCP can surface many of them in practice:
| Risk | How it manifests in MCP |
|---|---|
| Tool poisoning | A malicious tool server embeds hidden instructions in tool descriptions. The model follows them as if they came from the developer — redirecting behavior, exfiltrating data, or suppressing competing tools. OWASP catalogs this as MCP03:2025. |
| Prompt injection | Tool responses containing adversarial instructions alter the agent’s subsequent behavior. One tool call’s output becomes the next one’s input — poisoned data propagates through the agent’s reasoning unchecked. |
| Supply chain attacks | Dynamically discovered tool servers with typosquatted names or compromised definitions enter the agent’s available tool set. The agent trusts them the same as any other registered tool. |
| Cascading failures | An agent retries aggressively against an erroring MCP server and triggers a cascade that takes down downstream services. No circuit breaker exists in the protocol. |
We ran a red-team benchmark across these risks: 60 prompts (45 adversarial and 15 valid) mapped to the OWASP Agentic Top 10. Using prompt-only safety instructions (i.e., relying on the model to follow rules) resulted in a 26.67% policy violation rate in our internal red-team evaluation (see methodology below). In other words, more than one in four adversarial scenarios succeeded. As a result, instruction-following alone shouldn’t be treated as a security boundary.
Full methodology and reproduction instructions: BENCHMARKS.md
What’s missing: a governance layer between discovery and execution
The core issue is structural: MCP handles discovery, invocation, and response handling, but it doesn’t define a control plane that can decide whether a specific tool call should be allowed before it runs.
There’s a familiar precedent here. Mature systems don’t rely on applications to “do the right thing” around sensitive resources – they enforce boundaries through centralized, deterministic checks.
For MCP tool execution, that suggests an explicit enforcement layer between the agent’s intent and the tool server’s execution. The goal is deterministic policy evaluation for every call—allow, deny, or require approval – rather than relying on guardrails the model can interpret inconsistently.
Introducing the Agent Governance Toolkit
The Agent Governance Toolkit (AGT) is an open-source runtime governance layer that sits between an MCP client and the tool servers it connects to. It evaluates each tool call against policy before execution. AGT is currently in Public Preview, and some features and APIs may change before general availability.
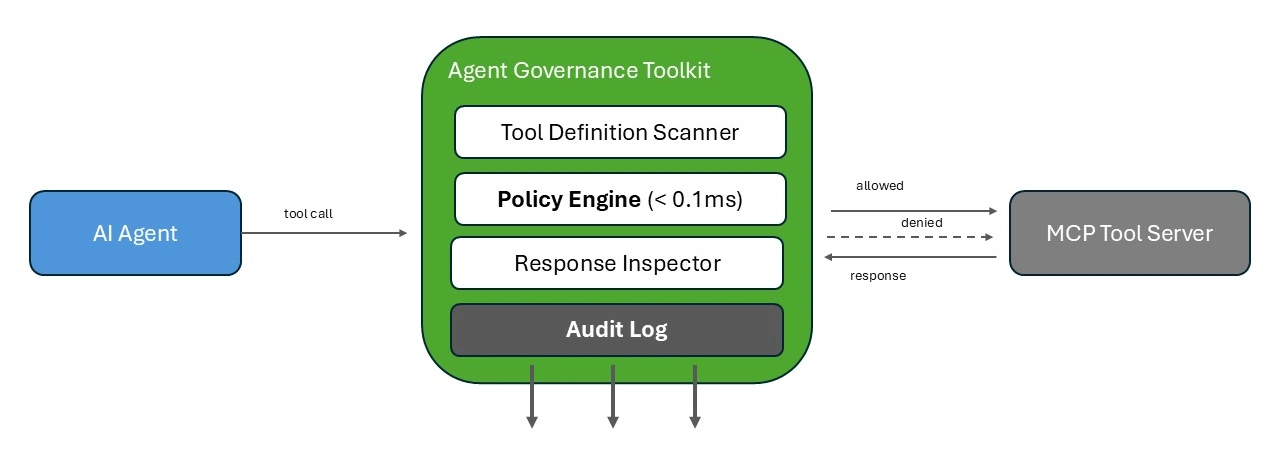
Figure: AGT governance pipeline — tool calls pass through definition scanning, policy evaluation, and response inspection.
AGT governs agent actions, not model outputs. It doesn’t filter what the model says — for that, see Azure AI Content Safety. AGT controls what the model is allowed to do. Here’s what it brings to MCP:
Tool definition scanning. Before an agent ever sees a tool description, AGT scans it for hidden instructions, typosquatting, and adversarial patterns. Poisoned definitions are flagged or blocked before they enter the model’s context.
Per-call policy enforcement. Declarative rules (YAML, OPA/Rego, or Cedar) are evaluated deterministically before every tool invocation. In our internal microbenchmarks (see methodology in the repo), policy evaluation added sub-millisecond overhead per call for typical rule sets. In most deployments, that overhead is small relative to an LLM round trip.
Response inspection. Tool server responses are validated against content policies before they’re returned to the agent. Poisoned outputs — adversarial instructions, data exfiltration payloads – are caught at the boundary.
Identity and trust. Agents receive cryptographic identities (Ed25519 + quantum-safe ML-DSA-65) with trust scores on a 0–1000 scale, built on SPIFFE-compatible identity. Trust decays on violations and can recover with compliant behavior. Agents are identified for every tool call.
Execution gating. A four-tier privilege ring model enforces least-privilege. Kill switches provide immediate termination for non-compliant agents.
Observability. Append-only, hash-chained audit logs record every tool call attempt, policy decision, and execution outcome. Replay debugging supports incident investigation.
| # | OWASP MCP Risk | Coverage |
|---|---|---|
| MCP01 | Token Mismanagement & Secret Exposure | Partial |
| MCP02 | Privilege Escalation via Scope Creep | Yes |
| MCP03 | Tool Poisoning | Yes |
| MCP04 | Software Supply Chain Attacks | Yes |
| MCP05 | Command Injection & Execution | Yes |
| MCP06 | Intent Flow Subversion | Partial |
| MCP07 | Insufficient Authentication & Authorization | Yes |
| MCP08 | Lack of Audit and Telemetry | Yes |
| MCP09 | Shadow MCP Servers | Partial |
| MCP10 | Context Injection & Over-Sharing | Yes |
AGT maps to the OWASP MCP Top 10 — 7 of 10 risks fully covered, 3 partial with roadmap items. It also maps to all 10 OWASP Agentic risk categories, supported by an automated test suite and continuous integration in the repo. AGT includes adapters and integrations for 20+ frameworks (for example: LangChain, AutoGen, CrewAI, Semantic Kernel, OpenAI Agents SDK, and Google ADK) and ships SDKs for Python, TypeScript, .NET, Rust, and Go.
An important note on scope: AGT governs individual tool calls deterministically. It does not yet correlate sequences of individually-allowed calls that may form a malicious workflow — that’s on the roadmap. The governance model also isn’t MCP-specific: it applies equally to REST APIs, function calls, inter-agent messages, or custom protocols. For a full accounting of what AGT does and doesn’t do, see Known Limitations & Design Boundaries.
What’s next
Three OWASP MCP risks remain partially covered — and they’re driving our near-term roadmap:
- MCP01 — Token Mismanagement: Expanding MCP-specific secret scanning patterns beyond the current CredentialRedactor coverage.
- MCP06 — Intent Flow Subversion: Deeper prompt-injection detection for adversarial instructions that alter agent reasoning mid-workflow.
- MCP09 — Shadow MCP Servers: Trust scoring and discovery controls for unregistered tool servers that enter the agent’s environment.
We’re exploring workflow-level policies that would evaluate tool call sequences (not just individual invocations) and intent declaration where agents would declare what they plan to do before doing it, so the policy engine can validate the plan up front. These capabilities are on our roadmap and are not yet available.
Get started:
- GitHub repo — MIT licensed, Public Preview
- Quick Start guide — zero to governed agents in 10 minutes
- Architecture and threat model
- Open an issue — feedback and questions welcome
The Agent Governance Toolkit is in Public Preview. Features and APIs may change before general availability. The information in this post is current as of April 2026.
0 comments
Be the first to start the discussion.